Performance considerations
1 Overview
2 Network configuration
2.1 Default Network configuration
2.2 Network configuration improvement
3 Maps updates
3.1 Projection update cap
3.2 Optimizing the Map updates
4 JVM options
5 Notes
6 See also
2 Network configuration
2.1 Default Network configuration
2.2 Network configuration improvement
3 Maps updates
3.1 Projection update cap
3.2 Optimizing the Map updates
4 JVM options
5 Notes
6 See also
In ARINC 661 The performance of the an ARINC 661 Server is mainly related to how it answers to the User Applications Buffers. Note that while the Server does not receives any Buffer, it will normally not use any or very few CPU time.

The main areas which can affect the Server performance are:
Also, if updates to the MapItems are received before this time are elapsed, the Server will store the associated MapItems characteristics in the received Buffers and perform the compute after the time has elapsed.
Be aware that too small a value for this property (or even setting it to 0, which means that the Server will try to update Maps as soon as it recives the Buffer), can lead to huge performance problems.
It is possible to change the behavior of the Server regarding the MapItems updates with the server.optimizeMapUpdates property: if set to true, MapItems which have not changed in the MapItems Buffer will be discarded.
Overview
The ARINC 661 Server runtime pipeline is event-driven, which means that its job is to:- Interpret pilot actions and send the associated events to the UA
- Decode UA messages and update the display
- Decode the Buffer in the Buffer reception Thread for the Channel associated with the Buffer
- Start an updating Task in the UI framework Thread
- Update the graphics in the UI framework Thread
×
![]()
The overall computing time is the sum of:- The Decoding time: the time to decode the Buffer. The processing time for the decoding is usually very small, because it is inherently very efficient in the Server, and also by default only the widget properties whch have changed are really updated
- The Invoking time: the time to start the updating Task the UI framework Thread. The processing time for the Invoking is also usually very small, it correspond to the time which is necessary for the Platform to start a new Thread on the UI Framemork and swtich to this Thread
- The Updating time: the time to update the graphics. This is the main time consumed by the Server in response to UA Buffers
The main areas which can affect the Server performance are:
Network configuration
Default Network configuration
The default configuration for the Network (if no Network configuration has been defined):- A Built-in UDP protocol with two separate ports for the input and output sockets. Using an UDP protocol means that:
- Some Buffers can be lost because the UDP Protocol does not guarantee the fact that messages are effectively received
- The orders of the Buffers reception is not guaranteed
- There can be some limit on the size of the Sockets, meaning that some Buffers can be truncated and sent on several consecutive messages (which can be unreadable, knowing that their ordering is not guaranteed)
- The Input event queue size is unlimited. This can lead to problems if the UA sends Buffers quicker than the Server can perform their associated updates. If it is the case, it means that the internal size of the queue will grow undefinitely until all the memory allocated to the JVM is used, an then the application will crash
Network configuration improvement
If there are a lot of Buffers sent from the UA to the CDS, it is often a good idea to separate cyclic data from event-driven data. For example:- Data which correspond to widget states (such as for example Buttons StyleSet) normally do not change often and should be sent though a Protocol which enforce the order of the reception and don't lost any Buffer
- Data which correspond to cyclic values (for example, a NumericReadout which present a temperature value) typically change often. In that case using an UDP protocol but not keeping any Buffer on the reception queue is better
network=networkconf.xml
The associated Network configuration could be:<network> <channel name="EventDrivenChannel"> <direction type="serverInput" port="8080" size="10000" /> <direction type="serverOutput" port="8081" size="150" /> <layerSet appli="1" /> <property key="protocol" value="tcp" /> <property key="maximumQueueSize" value="5"/> </channel> <channel name="CyclicChannel"> <direction type="serverInput" port="8083" size="10000" /> <direction type="serverOutput" port="8084" size="150" /> <layerSet appli="2" /> <property key="protocol" value="udp" /> <property key="maximumQueueSize" value="blocking"/> </channel> </network>Here we have defined two Channels:
- The EventDrivenChannel uses a TCP protocol because we don't want to lose any Buffer for event-driven data. Also we define a Event queue size of 5, meaning that we will store up to 5 received queues
- The CyclicChannel uses an UDP protocol because we don't mind losing a Buffer for cyclic data. Also we define a Event queue size of 1 (blocking), meaning that we won't store any received queue but process them as soon as they are received
Maps updates
Projection update cap
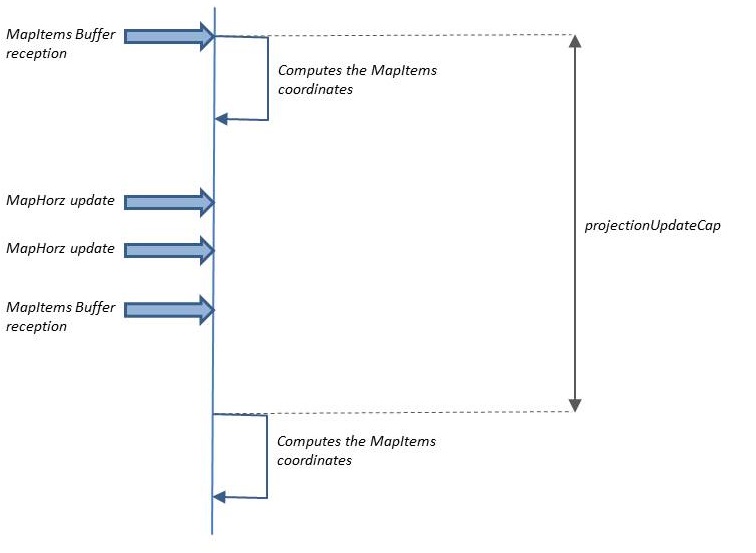
To avoid to be completely swamped by Map updates sent by the UA, the server.projectionUpdateCap property allows to specify at which rate the MapItems coordinates will be updated: This is the minimum time between two projection characteristics changes in Maps. The default is 160 ms, and 0 means that there is no cap at all. If two MapItemList buffers or MapHorz characteristics are received in less than this value, the Server will wait until this time has elapsed to compute the change.Also, if updates to the MapItems are received before this time are elapsed, the Server will store the associated MapItems characteristics in the received Buffers and perform the compute after the time has elapsed.
Be aware that too small a value for this property (or even setting it to 0, which means that the Server will try to update Maps as soon as it recives the Buffer), can lead to huge performance problems.
Optimizing the Map updates
Contrary to regular widgets, by default the Server considers that if it receives a MapItem in a Buffer, this mapitems has been updated (Even if none of its attributes has changed and its associated item Style has not changed).It is possible to change the behavior of the Server regarding the MapItems updates with the server.optimizeMapUpdates property: if set to true, MapItems which have not changed in the MapItems Buffer will be discarded.
JVM options
It has been discovered that in some cases the default Garbage Collector used in Java 8 is not ideal when used with the J661 Server (when working with high workloads). The observed general behavior of the default Java 8 GC (named "G1" or "Garbage-First Collector")[1]
See the Garbage-First Collector documentation
for a J661 Server is roughly the following:- The used memory is divided in "New Generation" (short lived objects) and "Old Generation" (long lived objects)
- The old generation is GCed when roughly 70% of the memory is used. This can happen after several hours, but just before this moment, we can observe a significant degradation of the application performance
See the Concurrent Mark and Sweep Collector documentation
allows to improve the performance of the application by processing old generation GC much more frequently. For example, the following options are useful:- -XX:+UseConcMarkSweepGC: use the CMS collector
- -XX:+UseCMSInitiatingOccupancyOnly: trigger the CMS collector on the occcupancy of the heap
- -XX:CMSInitiatingOccupancyFraction: define the fraction of the heap when the GC will happen
- -XX:NewRatio: define the fraction between the old and the new generation
-XX:+UseConcMarkSweepGC -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=20 -XX:NewRatio=3 -Xms512m -Xmx1024m
Notes
- ^ See the Garbage-First Collector documentation
- ^ See the Concurrent Mark and Sweep Collector documentation
See also
- Performance tools: This article is about the Server tools allowing to monitor the Server performance
- Server communication configuration: This article explains how to configure the Server Network communication
×
![]()
Categories: dev | performance | server | user